Hello mọi người!
Hôm nay mình sẽ deploy react app lên server sử dụng docker. Ok, vào việc luôn nhỉ?
Nội dung:
- Install Docker On Ubuntu 18.04.
- Dockerizing a React App with Nginx.
I. Install Docker On Ubuntu 18.04
- Truy cập vào server và cài các gói dịch vụ cần thiết:
sudo apt-get update
sudo apt-get install curl apt-transport-https ca-certificates software-properties-common
Bây giờ chúng ta thêm Repositories Docker
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
sudo apt update
Đảm bảo rằng bạn đang cài từ Docker repo thay vì Ubuntu repo bằng lệnh sau:
apt-cache policy docker-ce
Giờ chỉ cần dùng lệnh apt để install Docker lên Ubuntu
sudo apt-get install docker-ce
Kiểm tra tình trạng docker sau khi cài:
sudo systemctl status docker
À mình dùng cả docker compose nữa nên mình sẽ cài thêm bằng lệnh sau:
sudo apt-get install docker-compose
II. Dockerizing a React App with Nginx
- Đầu tiên chuẩn bị project reactjs.
1. Build Image
- Để dockerize một project trước hết chúng ta cần phải cấu hình Dockerfile để định nghĩa Image với môi trường và những thứ cần thiết cho project.
Cấu hình Dockerfile

1. Nói với thằng docker rằng t cần môi trường với Image có tên là node:10-alpine. Tại sao là alpine?
- Alpine Linux nhỏ hơn nhiều so với hầu hết các base Image khác (~ 5MB).
- Nhẹ, tối giản và tập trung vào bảo mật cao.
Giai đoạn này gọi là buid. ( as build )
2. Workdir /app: trong image tạo thư mục app và chuyển đến đường dẫn /app.
3. Copy toàn bộ code ở môi trường gốc.
4. Cài đặt các package.
5. Buid project.
6. Sang giai đoạn mới. FROM nginx:stable-alpine. Ý là nói với thằng docker là t cần thêm image nginx nữa.
Nginx là cái gì? Thì nginx ở đây là webserver. Nginx rất xịn nhé ( Khoai khi mới tiếp cập, khi đã giác ngộ thì bánh cuốn vc. Chắc sẽ viết thêm về nginx sau này).
7. Copy files build ở giai đoạn buid phía trước sang /usr/share/nginx/html, đây chính là nơi Nginx sẽ tìm tới và trả về cho user khi user truy cập ở trình duyệt.
8. Copy files config nginx sang.
9. App sẽ chạy ở port 80.
10. Khới động nginx.
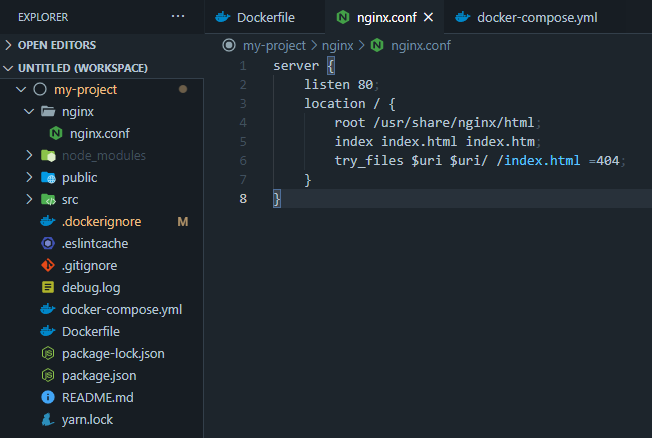
File config nginx.
File .dockerignore

File docker-compose.yml
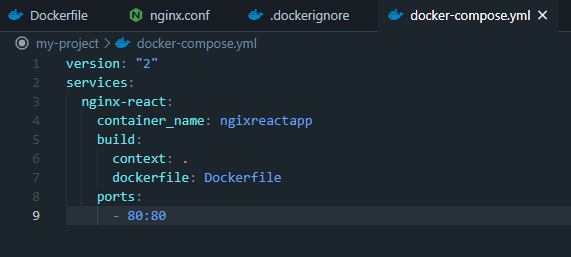
Đặt tên cho ứng dụng mình. Đề cập tới Dockerfile sử dụng. Mapping port 80 với port 80 của ứng dụng. ( port 80 bên trái là port của server - môi trường gốc, port 80 bên phải là port của container).
Giờ ta chỉ cần run container
docker-compose up
Chạy nền thì sử dụng: docker-compose -d up
Vậy là mình đã sử dụng docker để deploy react app lên server sử dụng công nghệ ảo hóa.
Lợi ích:
- Docker cho bạn môi trường mục tiêu cụ thể.
- Môi trường trong docker độc lập với môi trường gốc ( không bị xung đột, phụ thuộc lẫn nhau).
- Docker có nhiều tiện tích đi kèm ( Kubernetes: tự động scale, tự động deploy, tự động và tự động)
- .......
III. Docker
- Khái niệm: Docker là một dự án mã nguồn mở giúp tự động triển khai các ứng dụng Linux và Windows vào trong các container ảo hóa. Docker cung cấp một lớp trừu tượng và tự động ảo hóa dựa trên LinuxDocker là một dự án mã nguồn mở giúp tự động triển khai các ứng dụng Linux và Windows vào trong các container ảo hóa. Docker cung cấp một lớp trừu tượng và tự động ảo hóa dựa trên Linux.
- Docker có hai khái niệm chính cần hiểu, đó là image và container.
1. Image
- Image sẽ định nghĩa cho 1 môi trường và những thứ có trong môi trường đó. Ứng dụng của ta muốn chạy được thì cần phải có Image.
Ví dụ: trong image có thể định nghĩa các thành phần: Ubuntu, Mysql,...
- Để tạo Image ta cần tạo một Dockerfile.
Một số lệnh trong Dockerfile:
FROM <base_image>:<phiên_bản>: đây là câu lệnh bắt buộc phải có trong bất kỳ Dockerfile nào. Nó dùng để khai báo base Image mà chúng ta sẽ build mới Image của chúng ta.
MAINTAINER <tên_tác_giả>: câu lệnh này dùng để khai báo trên tác giả tạo ra Image, chúng ta có thể khai báo nó hoặc không.
RUN <câu_lệnh>: chúng ta sử dụng lệnh này để chạy một command cho việc cài đặt các công cụ cần thiết cho Image của chúng ta.
CMD <câu_lệnh>: trong một Dockerfile thì chúng ta chỉ có duy nhất một câu lệnh CMD, câu lệnh này dùng để xác định quyền thực thi của các câu lệnh khi chúng ta tạo mới Image.
ADD <src> <dest>: câu lệnh này dùng để copy một tập tin local hoặc remote nào đó (khai báo bằng <src>) vào một vị trí nào đó trên Container (khai báo bằng dest).
ENV <tên_biến>: định nghĩa biến môi trường trong Container.
ENTRYPOINT <câu_lệnh>: định nghĩa những command mặc định, cái mà sẽ được chạy khi container running.
VOLUME <tên_thư_mục>: dùng để truy cập hoặc liên kết một thư mục nào đó trong Container.
WORKDIR: Thiết lập thư mục đang làm việc cho các chỉ thị khác như: RUN, CMD, ENTRYPOINT, COPY, ADD,…
EXPOSE: khai báo port lắng nghe của image
Câu lệnh build image:
docker build -t “name image” .
Ở cuối có 1 dấu "chấm" ý bảo là Docker hãy build Image với context (bối cảnh) ở folder hiện tại này. Và Docker sẽ tìm ở folder hiện tại Dockerfile và build.
Để show: docker images
Xóa image: docker rmi “mã image”
2. Container
- Container: Tương tự như một máy ảo, xuất hiện khi mình khởi chạy image.
docker container run -p port:port “name images”
-p port:port ( port trái là port môi trường gốc, port phải là port của container
Truy cập vào container và gắn terminal bash vào nó
docker exec -it <container id> /bin/bash
Cảm ơn mọi người đã đọc đến đây. Nếu cảm thấy hay và có ích thì hãy chia sẻ để mọi người cùng biết thêm kiến thức.
Tài liệu tham khảo:
https://docs.docker.com/get-started
https://dev.to/bahachammakhi/dockerizing-a-react-app-with-nginx-using-multi-stage-builds-1nfm
https://viblo.asia/p/docker-nhung-kien-thuc-co-ban-phan-1-bJzKmM1kK9N